1 | 原文:https://webapplog.com/you-dont-know-node/ |
你不知道的Node:核心特性的快速介绍

这篇文章是由Kyle Simpson的系列书籍You-Dont-Know-JS所启发。它们是很好的JavaScript基础入门书籍。除了一些我将会在文章中强调的不同,Node基本上就是JavaScript。代码在you-dont-know-node github仓库下的code文件夹下。
为什么在意Node?Node是JavaScript而JavaScript几乎要占领世界了。如果更多开发者掌握Node这个世界岂不是变得更好?更好的应用等于更好的人生!
这是一个主观的最有趣核心特性大合集。这篇文章的重点如下:
- Event loop(事件循环):温习下使非阻塞I/O成为可能的核心概念
- Global(全局变量) 和 process(进程):如何获得更多信息
- Event emitters(事件发射器):基于事件模式的速成课
- Streams(流) 和 buffers(缓冲区):处理数据的高效方式
- Clusters(集群):像一个专家一样fork进程
- 处理异步错误:AsyncWrap,Domain和uncaughtException
- C++扩展:给核心做贡献并写你自己的C++扩展
Event Loop(事件循环)
我们可以从Node的核心事件循环开始
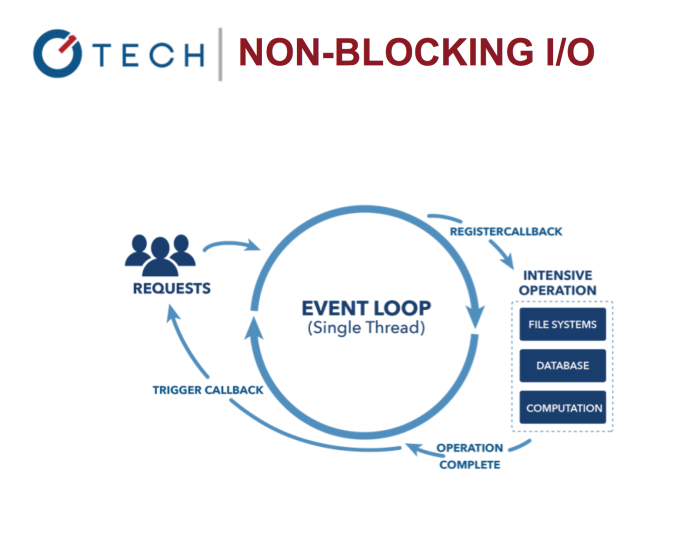
Node.js Non-Blocking I/O
它允许在处理IO调用的过程中处理其他任务。想想看Nginx vs. Apache。它让Node更快更有效率,因为阻塞式I/O十分昂贵!
看下这个在 java 中基础的延迟 println 函数的例子:
1 | System.out.println("Step: 1"); |
和Node代码是可比较的(实际上不可比较):
1 | console.log('Step: 1') |
实际并不太相同。你需要开始用异步的方式思考。Node脚本输出是1,2,3,但如果我们在“Step 2”后放更多语句,它们将会在setTimeout回调之前运行。看看以下片段:
1 | console.log('Step: 1') |
最终产出1,2,4,3,5。这是因为setTimeout把它的回调放入事件循环的未来周期中了。
把事件循环想象成一个永远旋转的循环就像for循环或者while循环。它只有在现在或者未来没有东西去执行的时候才会停止。
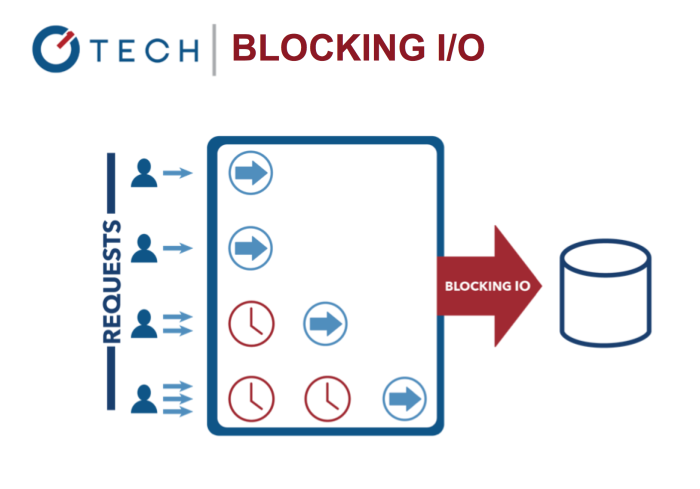
Blocking I/O: Multi-Threading Java
事件循环让你的系统更加的有效率,因为现在你可以在你等待你昂贵的输入输出任务结束的时候,你可以做更多事情。
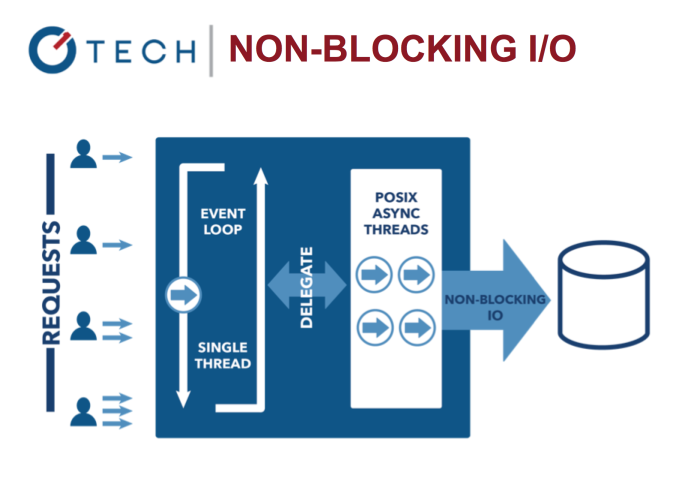
Non-Blocking I/O: Node.js
这与我们当前的直接使用系统线程的并发模型做对比。基于线程的网络设计相对来说更没有效率更难用。此外,Node的使用者不用担心进程的死锁,因为根本就没有锁。
小边注:那么我们仍然可能在Node中写阻塞代码吗?思考下面这个简单但是阻塞的Node代码:
1 | console.log('Step: 1') |
当然,一般情况下,我们不会在我们的代码中写空循环。指出同步因此当我们使用他人的模块的时候,阻塞式代码可能更难。比如,核心的fs模块就有两组方法。每组执行相同的功能但用不同的方式。阻塞的fsNode方法在名字上带有Sync:
1 | var fs = require('fs') |
结果即使Node/JavaScript新手来说也很容易猜出
1 | data1->Hello Ruby->data2->Hello NODE! |
当我们转为异步方法,就不一样了。这是非阻塞的Node代码:
1 | var fs = require('fs'); |
将会最后打印contents因为需要一段时间去执行,他们在回调中。事件循环将会在文件读取结束的时候调用他们:
1 | Hello Python->Hello Node->data1->data2 |
所以事件循环和非阻塞I/O非常强大,但你需要写异步代码,然而我们大部分在学校都不是学习这种代码。
Global(全局)
当从浏览器JavaScript或者其他编程语言转到Node,会有下面几个问题:
- 哪里去存储密码?
- 如何创建全局变量(在Node中没有window)
- 如何获得命令行输入,操作系统,平台,内存使用,版本等等?
有一个全局对象,它有一些属性。部分如下:
global.process: 进程,系统,环境信息(你可以获得命令行输入,环境变量比如密码,内存等)global.__filename: 文件名和当前运行脚本的路径global.__dirname: 当前运行脚本的绝对路径global.module: 对象用于导出代码,使这个文件变为一个模块global.require(): 导入模块,JSON文件,和文件夹的方法
接下来就是我们熟悉的来自浏览器JavaScript的方法:
- global.console()
- global.setInterval()
- global.setTimeout()
每一个全局属性都可以通过大写的GLOBAL或者干脆没有命名空间比如process代替global.process
Process(进程)
Process对象有许多信息,理应做成一个部分。我列出其中的一些属性:
- process.pid:这个Node实例的进程ID
- process.versions:Node,V8和其他组件的各种版本
- process.arch:系统的架构
- process.argv:命令行参数
- process.env:环境变量
一些方法如下:
- process.uptime():获取uptime
- process.memoryUsage():获取内存使用
- process.cwd():获取当前工作目录。不要与
__dirname混淆,后者不依赖于启动进程的位置。 - process.exit():退出当前进程。你可以传入1或0。
- process.on():添加一个事件监听器比如’on(‘uncaughtException’)’
棘手的问题:谁会喜欢并且理解回调??
一些人太喜欢回调了,于是他们创建了http://callbackhell.com。如果你还不熟悉这个术语,以下是展示:
1 | fs.readdir(source, function (err, files) { |
回调地狱难以阅读,并且容易出错。除此之外回调并不能很好的扩展,那么我们该如何模块化和管理异步代码?
Event Emitters(事件发射器)
为了解决回调地狱,或者说末日金字塔,我们有了Event Emitters。他们允许你用事件的方式执行异步代码。
简单来说,event Emitters就是你触发了一个事件,所有有监听这个事件的都可以听到。在Node中,一个事件可以描述为一个字符串和一个响应的回调。
Event Emitters为了以下目的:
- 用观察者模式处理Node中的事件处理
- 一个事件追溯所有与之相关联的函数
- 这些相关联的函数,我们称之为观察者,当对应事件被触发的时候执行
为了使用Event Emitters,导入模块并实例化对象:
1 | var events = require('events') |
之后,我们添加事件监听器然后触发事件:
1 | emitter.on('knock', function() { |
让我们通过继承EventEmitter来实现一些更有用的。想象你的任务是实现一个类来完成每月,每周和每日的邮件工作。这个类需要足够灵活能够让开发者去自定义最终的输出。换句话说,任何人消费这个类需要在工作结束的时候做一些自定义的逻辑。
下面这个图解解释了我们继承events模块去创建Job,然后我们使用done事件监听器去自定义Job类的行为:
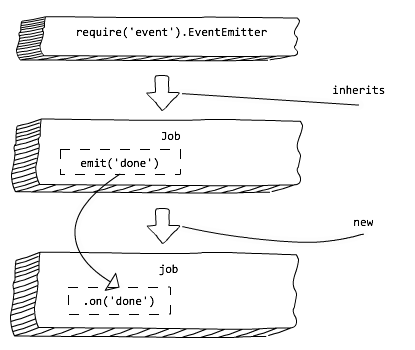
Node.js Event Emitters: Observer Patterns
类Job将会保持它的属性,但也会得到events。我们需要做的只是在结束的时候触发done即可:
1 | // job.js |
现在,我们的目标是自定义Job任务结束后的行为:
1 | // weekly.js |
还有一些emitters的其他功能:
- emitter.listeners(eventName):列出相应事件的对应的所有事件监听器
- emitter.once(eventName, listener):添加一个只触发一次的事件监听器
- emitter.removeListener(eventName, listener):移除一个事件监听器
事件模式在Node中广泛应用,特别是在核心模块。所以,掌握事件将会给你一个很大的提升。
Streams(流)
当Node中处理大的数据的时候有一些问题。速度可能会很慢并且buffer的限制是1Gb。并且,如果资源是持续的,没有设置尽头的,你改如何处理?为了解决这些问题,使用streams(流)。
Node流是持续的数据块的抽象。换句话说,不需要等待整个资源被加载。看下下面的图解展示了标准的buffer的处理方式:
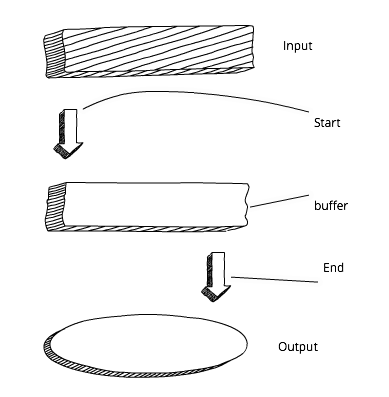
Node.js Buffer Approach
我们必须等到全部的buffer加载之后,才可以处理输出的数据。接下来,对比下一个描绘流的图解。这下,我们可以从收到的第一个数据块开始马上处理数据:
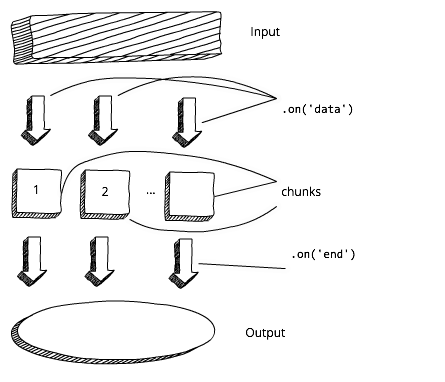
Node.js Stream Approach
在Node中有四种类型的Streams:
- Readable:可读
- Writable:可写
- Duplex:即可读也可写
- Transform:你可以转换数据
事实上在Node中Streams到处都是。最常见的stream实现是:
- HTTP请求和响应
- 标准输入/输出
- 文件读取和写入
Streams继承自Event Emitter,使其提供观察者模式,比如events,还记得吗?我们可以用它来实现流。
可读流例子
一个可读流的例子可以是标准输入流process.stdin。它包含了进入应用的数据。典型的输入是从键盘用来开始进程。
为了读取从stdin读取数据,使用data和end事件。data事件的回调将会把数据块作为参数传入:
1 | process.stdin.resume() |
然后数据块便输入至程序。根据输入的大小,事件可能会触发多次。end事件是用于输入流最后的信号。
提示:stdin默认是停止的,所以在读数据之前要resume(恢复)。
可读流有一个同步的read()接口。当流结束的时候,它返回数据块或者null。于是我们可以利用这种特性把null !== (chunk = readable.read())放入while的条件中:
1 | var readable = getReadableStreamSomehow() |
理想情况下,我们想尽量在Node中多写异步代码,为了避免阻塞主线程。然而,数据块很小,所以不必担心同步的readable.read()阻塞线程。
Pipe(管道)
Node为开发者提供了一个事件的替代方案。我们可以使用pipe()方法。下面的例子为读一个文件,用GZip压缩,然后把压缩的数据写入文件:
1 | var r = fs.createReadStream('file.txt') |
Readable.pipe()接受一个可写流然后返回一个终点。这样我们就可以把pipe()方法一个一个串联起来。
所以你使用流的时候在events和pipes之间就可以选择了。
HTTP Streams(HTTP流)
我们大部分使用Node构建传统或者RESTful Api的web应用。所以我们可以把HTTP请求变为流吗?答案是一个响亮的yes。
请求和响应都是可读可写的流并且都继承event emitters。我们可以添加一个data事件监听器。在回调中我们接收数据块,我们马上转化数据块而无需等到全部的响应。在下面的例子中,我拼接body并在end事件的回调中解析:
1 | const http = require('http') |
接下来我们使用Express.js让我们的服务更加接近真实情况。在下一个例子中,我有一个巨大的图片(~8Mb)并且有两组路由:/stream和/non-stream。
server-stream.js:
1 | app.get('/non-stream', function(req, res) { |
我在/stream2中也有一个替代事件的实现并且在/non-stream2中有一个替代同步的实现。他们做的事是一样的,只不过是用了不同的语法和风格。在这个例子中同步方法性能表现会更好,因为我们只发送了一个请求,而不是同时多个。
为了启动例子,在命令行中输入:
1 | $ node server-stream |
接下来在chrome中打开http://localhost:3000/stream和http://localhost:3000/non-stream。在开发者工具中的Network标签页中将会向你展示headers。对比X-Response-Time。在我的例子中,是数量级的差距, /stream vs. /stream2:300ms vs. 3–5s。
你的结果可能不一样,但我想表达的意思是使用流,用户可以更早的得到数据。Node的流确实很强大。这里有一些好的关于流的资源,掌握了它们然后在你的团队中成为一个流的专家。
Stream Handbook和stream-adventure你可以通过npm安装:
1 | $ sudo npm install -g stream-adventure |
Buffers
对于二进制数据我们使用什么类型?如果你记得的话,浏览器JavaScript没有二进制类型,但是Node有。我们称之为buffer。是一个全局对象,所以我们不用把他当作模块导入。
创建二进制类型,使用下面的声明之一:
- Buffer.alloc(size)
- Buffer.from(array)
- Buffer.from(buffer)
- Buffer.from(str[, encoding])
官方[Buffer文档]列出所有的方法和编码。最流行的编码是utf8。
一个典型的buffer看起来像是乱码,所以我们必须用toString()把它转化为人类可读的格式。下面的for循环创建一个字母表的buffer:
1 | let buf = Buffer.alloc(26) |
如果我们不把它转化为字符串,这个buffer看起来就像一个数字的数组。
1 | console.log(buf) // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a> |
如果我们用toString把它转化为字符串
1 | buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz |
如果我们只是需要部分的字符串,这个方法接收开始数字和结束位置:
1 | buf.toString('ascii', 0, 5) // outputs: abcde |
还记得fs吗?默认情况下data的值也是buffer:
1 | fs.readFile('/etc/passwd', function (err, data) { |
Clusters(集群)
你可能经常从Node怀疑者那听到说Node是单线程的,所以它没法规模化。有一个核心模块cluster(核心模块意味着你不用安装,它是平台的一部分)允许你利用每个机器的所有CPU能力。这允许你垂直的扩展你的Node程序。
代码是很简单的。我们需要引入模块,创建一个master,和多个worker。典型的我们有多少个CPU核心就创建多少个进程。但这不是硬性规定。你可创建任意数量的进程,但到某一个点,收益递减规律介入,你不会有任何性能提高。
master和worker的代码在同一个文件。worker可以监听同一个端口并且发送消息(通过事件)给master。master可以监听事件并且在需要的时候重启cluster。为master写代码的方式是使用cluster.isMaster(),对worker来说就是cluster.isWorker()。大部分服务器代码都放在worker(isWorker())。
1 | // cluster.js |
在cluster.js例子中,我的服务器输出进程ID,因此你可以看到不同的worker处理不同的请求。这就像负载均衡,但这不是真正的负载均衡,因为负载没有平均的分散。你可能看到大量的请求在同一个进程中(PID会一样)。
为了看到不同的worker服务不同的请求,使用loadtest,一个基于Node的压力测试工具:
- 通过npm安装
loadtest:$ npm install -g loadtest - 使用node运行
code/cluster.js($ node cluster.js);让server运行 - 运行负载测试:
$ loadtest http://localhost:3000 -t 20 -c 10在一个新的窗口 - 同时在服务终端和loadtest终端分析结果
- 当测试结束的时候在终端按下control+c。你应该看到不同的PID。写下请求服务的数字。
-t 20 -c 10负载测试命令意味着将会有10并发请求,最大时间为20秒。
自带的集群唯一的优势就是核心的一部分。当你准备发布到生产,你应该想要更先进的进程管理工具:
strong-cluster-control(https://github.com/strongloop/strong-cluster-control)pm2(https://github.com/Unitech/pm2)
pm2
来谈谈pm2,被认为是一种横向扩展你的Node应用的方式(最好的方式之一),并且有着生产级别的性能和特性。
总的来说,pm2有以下几种优势:
- 负载均衡和其他特性
- 系统宕机重启
- 好的测试覆盖
pm2的文档在这 https://github.com/Unitech/pm2 和 http://pm2.keymetrics.io。
看一下下面的这个作为pm2例子的Express服务。这里没有样板代码isMaster(),这样很好,因为你不用改变你的源码,就像我们在cluster中做的那样。我们只需要打印pid并且观察他们。
1 | var express = require('express') |
使用pm2启动server.js来使用这个pm2例子。你可以传入需要复制的进程数(-i 0 意味着CPU的数量,在我的例子中是4个)并且将日志放入一个文件中(-l log.txt):
1 | $ pm2 start server.js -i 0 -l ./log.txt |
另一个pm2的优点是前台。想看当前运行,执行:
1 | $ pm2 list |
接下来,就像我们在cluster例子中做的那样使用loadtest。在一个新窗口,运行命令:
1 | $ loadtest http://localhost:3000 -t 20 -c 10 |
你的结果也许和我的不一样,但是我在log.txt中差不多得到了平均分散的结果:
1 | cluser 67415 responded |
Spawn vs Fork vs Exec
既然我们在cluster.js的例子中使用fork()来创建Node服务的新实例,那就有必要来提下在Node中的三种方式来启动一个外部的进程。他们是spawn(), fork() 和 exec()并且他们三个都来自核心模块child_process。他们之间的区别总结如下:
require('child_process').spawn():用于大的数据,支持流,可以用于任何命令,并且不创建新的V8实例require('child_process').fork():创建一个V8实例,实例化多个worker,只能用于Node.js脚本(node命令)require('child_process').exec():使用buffer,让其不适合大的数据或者流,以异步的方式让你在回调中一下获取全部的数据,并且可以用于所有命令
看下下面这个例子,我们执行node program.js,但我们也可以执行bash,Python,Ruby或任意其他的命令或脚本。如果你需要给命令传入额外的参数,只需要把需要参数作为数组传入spawn()。数据作为流在data事件传入:
1 | var fs = require('fs') |
从node program.js命令的角度来看,data是它的标准输出,比如,node program.js的终端输出。
fork()的语法和spawn()相似,除了没有命令,因为fork()假定所有的进程都是Node.js:
1 | var fs = require('fs') |
最后一项是exec()。这个有点不同,因为它没有使用事件模式,只是一个简单的回调。在回调中,你有错误,标准输出和标准错误参数:
1 | var fs = require('fs') |
errorandstderr的不同之处在于前者来自exec(),而后者来自你运行着的命令的错误。
Handling Async Errors
说到报错,在Node.js和其他几乎所有编程语言中,我们使用try/catch处理错误。对于同步错误,try/catch处理的不错:
1 | try { |
模块或者函数抛出错误,而后我们catch。这种对Java或者同步Node有效果。但是,Node的最佳实践是写异步代码,所以我们不阻塞线程。
事件循环让系统调度,使得昂贵的输入/输出任务结束的时候,执行相应的代码。但是伴随着异步错误,系统丢失了错误的上下文。
比如,setTimeout()异步使得回调在未来被调用。这有点像,HTTP请求,数据库读取或者写文件的异步函数:
1 | try { |
当回调被执行的时候,没有catch到,接下来应用崩溃。当然如果你在回调中放一个try/catch,会catch到错误,但这不是一个好的解决方案。这些讨厌的异步错误难于调试和处理。try/catch不足以处理异步错误。
那么异步报错无法catch。我们该怎么处理??你已经见过大部分的回调会有一个error参数。开发者需要去检查错误,并在回调中冒泡上去:
1 | if (error) return callback(error) |
其他处理异步错误的最佳实践如下:
- 监听所有“on error”事件
- 监听
uncaughtException - 使用domain或者AsyncWrap
- 打印与跟踪
- 提示(可选)
- 退出或重启
on(‘error’)
监听所有on(‘error’)事件,这些事件大部分由核心Node对象特别是http触发的。并且,任何继承http或者Express.js, LoopBack, Sails, Hapi等实例都会触发error事件,因为这些框架继承自http:
1 | // js |
uncaughtException
一定要在process对象上监听uncaughtException事件。uncaughtException是一个非常原始的异常处理机制。一个未处理的异常意味着你的应用-包括你的Node本身-是一个异常状态。盲目的恢复意味着什么都有可能发生。
1 | process.on('uncaughtException', function (err) { |
或者
1 | process.addListener('uncaughtException', function (err) { |
Domain
Domain和浏览器上的web域没有关系。domain是一个Node核心模块,可以通过保存异步代码执行的上下文来处理异步错误。一个domain基本的用法是实例化它然后把你的报错代码放入run()的回调中:
1 | var domain = require('domain').create() |
domain在4.0版本被软弃用了,意味着Node核心团队将会把domain同平台分离,但是现在核心还暂时没有domain的替代品。并且,因为domain有着很好的支持和使用,它会继续独立作为npm模块的一份子,这样你可以轻易的从核心转移到npm模块,意味着domain还生存的很好。
让我们用setTimeout再创建一个异步错误:
1 | // domain-async.js: |
代码不会崩溃!我们将会得到一个很好的错误信息,从domain的错误事件处理函数得到的“Custom Error”错误,而不是典型的Node堆栈跟踪。
C++ Addons(C++扩展)
Node在硬件,IoT和机器人流行的原因是Node可以很好的适应底层的C/C++代码。那么我们该如何为你的IoT,硬件,机器人,智能设备写C/C++ binding代码?
这是这篇文章的最终章节。大部分的Node初学者甚至认为你不能够写自己的C++扩展!事实上,这很简单,我们从头开始来。
首先,创建hello.cc文件,这个文件在开头有着一些样板引用。接下来我们定义一个方法,这个方法返回一个字符串并导出这个方法。
1 | #include <node.h> |
即使你不是C的专家,也很容易看出发生了是吗,因为这和JavaScript的语法也不是天壤之别。字符串是capital one:
1 | args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one"));` |
导出的名字是hello:
1 | void init(Local<Object> exports) { |
一旦hello.cc准备好了,我们还需要做一些事。其中一件是创建binding.gyp,包含着源代码文件名和扩展的名称:
1 | { |
把binding.gyp保存在hello.cc相同的文件夹下并在安装node-gyp:
1 | $ npm install -g node-gyp |
安装完node-gyp之后,在hello.cc和binding.gyp的同级文件夹下运行配置和构建命令
1 | $ node-gyp configure |
这些命令将会创建build文件夹。检查下在build/Release/下编译好的.node文件。
最后,创建一个Node脚本hello.js然后将你的C++扩展引入:
1 | var addon = require('./build/Release/addon') |
$ node hello.js`
Summary(总结)
上面的实例代码都在github。如果你对Node的模式比如观察者模式,回调和Node惯例感兴趣,看下我的这篇Node Patterns: From Callbacks to Observer。
我知道这是一篇长阅读,所以来个30秒的总结:
- 事件循环:Node非阻塞I/O背后的原理
- Global和process:全局对象和系统信息
- Event Emitters:Node的观察者模式
- 流:大体积数据的模式
- Buffers:二进制数据类型
- Clusters:垂直扩展
- Domain:异步错误处理
- C++扩展:底层扩展
Node的大部分就是JavaScript,除了一些核心特性大部分用于处理系统访问、全局变量、外部进程和底层代码。如果你理解了这些概念,你就踏上了掌握Node的快车道。