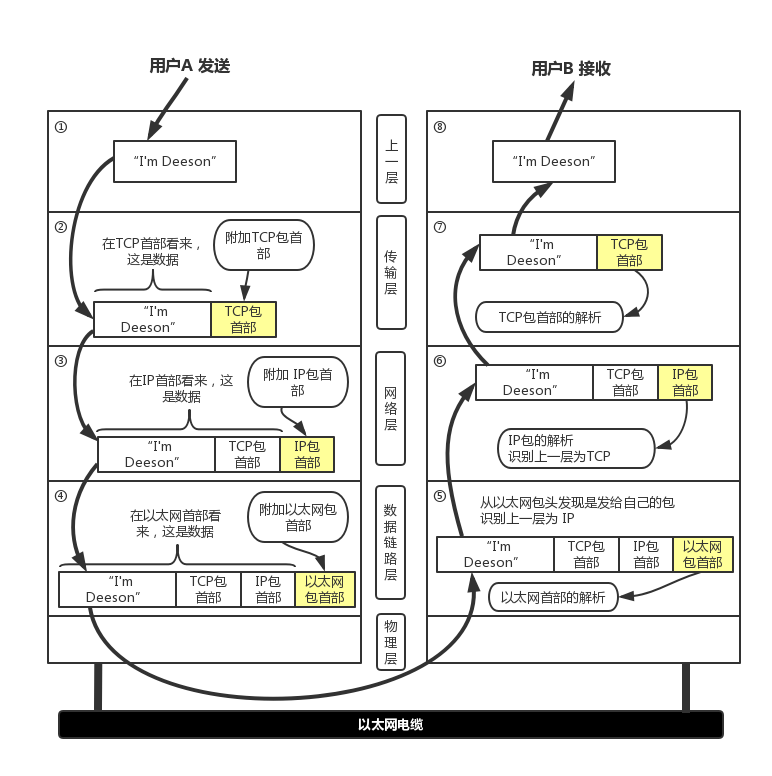
一些mongoDB常用的操作
基本概念
mongoDB中的一些基本概念与SQL的基本概念是不同的,这是我们学习mongoDB的时候需要注意与区分的。
下面一个表格带我们来理解下mongoDB中的一些概念。
| SQL概念 | mongoDB概念 | 说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,mongoDB不支持 | |
| primary key | primary key | 主键,mongoDB自动将_id字段设置为主键 |
通过下图,更加直观的理解mongoDB的一些概念
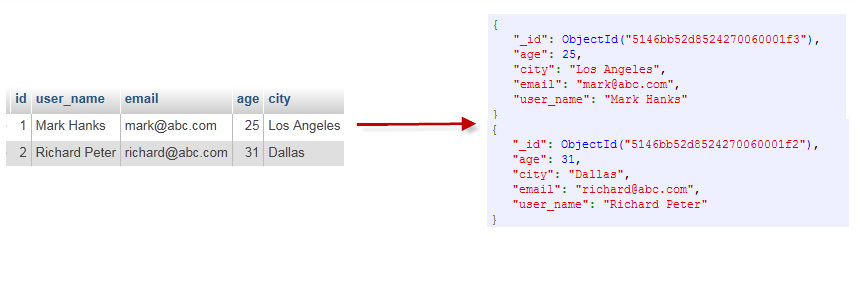
数据库
一个mongoDB可以建立多个数据库
通过命令show dbs来展现当前有多少数据库,名字分别叫什么
文档(document)
在mongoDB中文档就是一组键值对(key-value)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
需要注意的点
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
集合(collection)
集合就是mongoDB文档组,类似关系型数据库中的表。一个数据库中有多个集合,可以用命令show collections来查看。集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
MongoDB 数据类型
下表为MongoDB中常用的几种数据类型。
| SQL概念 | mongoDB概念 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
创建数据库
直接使用use命令创建数据库。如果数据库不存在,则创建数据库,否则切换到指定数据库。
1 | use DATABASE_NAME |
使用show dbs展示当前已创建的数据库。
use数据库之后db命令表示当前数据库
删除数据库
使用下列命令删除数据库1
db.dropDatabase()
使用下列命令删除集合1
db.collection.drop()
插入数据
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:1
db.COLLECTION_NAME.insert(document)
document采用json语法
3.2 版本后还有以下几种语法可用于插入文档:
- db.collection.insertOne():向指定集合中插入一条文档数据
- db.collection.insertMany():向指定集合中插入多条文档数据
更新文档
update() 方法用于更新已存在的文档。语法格式如下:1
2
3
4
5
6
7
8
9db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc…)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
删除文档
remove() 方法的基本语法格式如下所示:
1 | db.collection.remove( |
如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
1 | db.collection.remove( |
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。
另:
remove() 方法已经过时了,现在官方推荐使用 deleteOne() 和 deleteMany() 方法。
查询文档
MongoDB 查询数据的语法格式如下:
1 | db.collection.find(query, projection) |
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
1 | >db.col.find().pretty() |
pretty() 方法以格式化的方式来显示所有文档。
总结
以上是一些最基本的mongoDB的常用操作,若想看一些详情的文档和功能可以看官方的文档和一些教程。
参考